


Python + IA: Fundamentos e Projetos Práticos














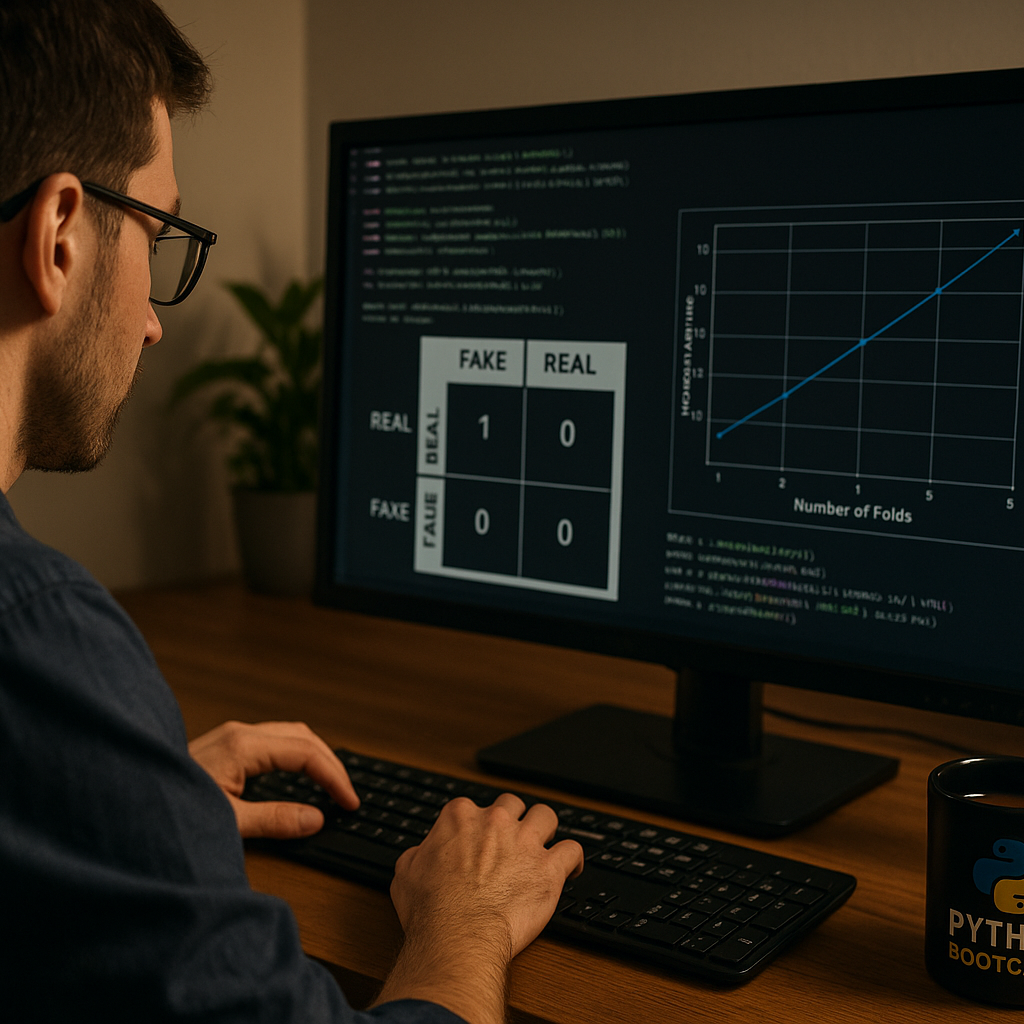
Hoje você vai aprender a avaliar o desempenho do seu modelo com muito mais profundidade.
Não basta saber que ele acerta 90% — é preciso saber o que ele está acertando, o que está errando, e por que isso importa.
🧠 Por que a acurácia não basta?
Imagine que 90% do seu dataset é composto por notícias reais. Um modelo que simplesmente classifica tudo como REAL vai ter 90% de acurácia — mas não serve pra nada.
É aqui que entram outras métricas fundamentais:
| Métrica | Explicação rápida |
|---|---|
| Precisão | Das previsões positivas, quantas estavam certas? |
| Revocação | Das amostras positivas, quantas o modelo encontrou? |
| F1-Score | Equilíbrio entre precisão e revocação |
| Matriz de confusão | Visual dos acertos e erros por classe |
🧰 O que vamos usar
classification_reportconfusion_matrixseabornoumatplotlibpara visualização
📦 Instale os pacotes (se ainda não tiver)
pip install scikit-learn matplotlib seaborn✍️ Código Python – Avaliação com Métricas Reais
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# Carrega o dataset
df = pd.read_csv("fake_news_dataset_v2.csv")
df = df[['text', 'label']].dropna()
# Divide dados
X_train, X_test, y_train, y_test = train_test_split(
df['text'], df['label'], test_size=0.3, random_state=7
)
# Vetoriza texto
vectorizer = TfidfVectorizer(stop_words='english', max_df=0.7)
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
# Modelo
model = LogisticRegression()
model.fit(X_train_vec, y_train)
y_pred = model.predict(X_test_vec)
# Avaliação textual
print("🔍 Relatório de Classificação:")
print(classification_report(y_test, y_pred))
# Matriz de Confusão
matriz = confusion_matrix(y_test, y_pred, labels=["FAKE", "REAL"])
sns.heatmap(matriz, annot=True, fmt='d', cmap='Blues',
xticklabels=["FAKE", "REAL"],
yticklabels=["FAKE", "REAL"])
plt.title("Matriz de Confusão")
plt.xlabel("Previsto")
plt.ylabel("Real")
plt.show()✅ O que você aprendeu hoje
- Que acurácia não conta a história toda
- Como usar métricas profissionais para avaliar um modelo
- Como interpretar uma matriz de confusão
- Que cada métrica responde a uma pergunta diferente sobre o desempenho
🎯 Desafio
- Teste com datasets desbalanceados
- Experimente trocar o modelo por
MultinomialNB() - Crie uma função que imprima as métricas de forma personalizada, mostrando emojis de erro e acerto






