

- Ambiente, Sintaxe Básica e Variáveis em Python — Bootcamp Dia 1
- Como Trabalhar com Listas no Python — Bootcamp Dia 6
- Tuplas e Sets em Python — Estruturas Imutáveis e Conjuntos Inteligentes | Bootcamp Dia 7
- Dicionários em Python: chave e valor, o jeito inteligente de armazenar dados
- Funções em Python: Escreva Menos, Faça Mais
- Tratamento de Erros em Python: programe com segurança
- Leitura e Escrita de Arquivos em Python: salve seus dados no mundo real
- Salvando Dados Estruturados com JSON em Python
- Funções com Múltiplos Retornos em Python: eficiência e organização
- Parâmetros Opcionais e Valores Padrão em Python
- *args e **kwargs em Python: flexibilidade total nas funções
- List Comprehensions em Python: código elegante e eficiente
- Manipulando Arquivos CSV com Python: automatize leitura e escrita de dados
- Começando com Pandas em Python: análise de dados para IA e automações
- Limpeza e Transformação de Dados com Pandas: preparando para IA
- Inteligência Artificial com Python: Fundamentos e Primeira Integração com a OpenAI
- Classificação de Texto com IA: Detectando Temas e Categorias
- Geração de Texto com IA: Criando Respostas Inteligentes com Python
- Chatbot com IA em Python: Construindo um Assistente Inteligente
- Como Detectar Fake News com Python e IA
- Como Criar uma Interface com IA em Python para Detectar Fake News
- Como Avaliar a Qualidade de um Modelo de IA com Python — Além da Acurácia
- Como Balancear Dados e Validar Modelos com Python e IA
- Projeto Final: Criando um Classificador de Fake News com Interface Web em Python (Streamlit)
Fala Dev! Chegamos ao fim do módulo Python + IA: Fundamentos e Projetos Práticos. Hoje você vai criar o seu primeiro aplicativo de IA com interface web real, executável no seu navegador.
Vamos usar o Streamlit, uma biblioteca que transforma scripts Python em aplicações web interativas com apenas uma linha de comando.
🧠 O que é o Streamlit?
📌 Streamlit é uma ferramenta que permite criar apps web com Python puro, ideal para protótipos de IA, visualizações de dados, dashboards e experimentos de machine learning.
✅ Por que usar Streamlit?
- Interface pronta sem precisar saber HTML/CSS
- Fácil de usar:
pip install streamlit - Executa localmente com
streamlit run arquivo.py - Ótimo para demonstrações, testes e produtos mínimos viáveis (MVP)
🔧 O que vamos construir?
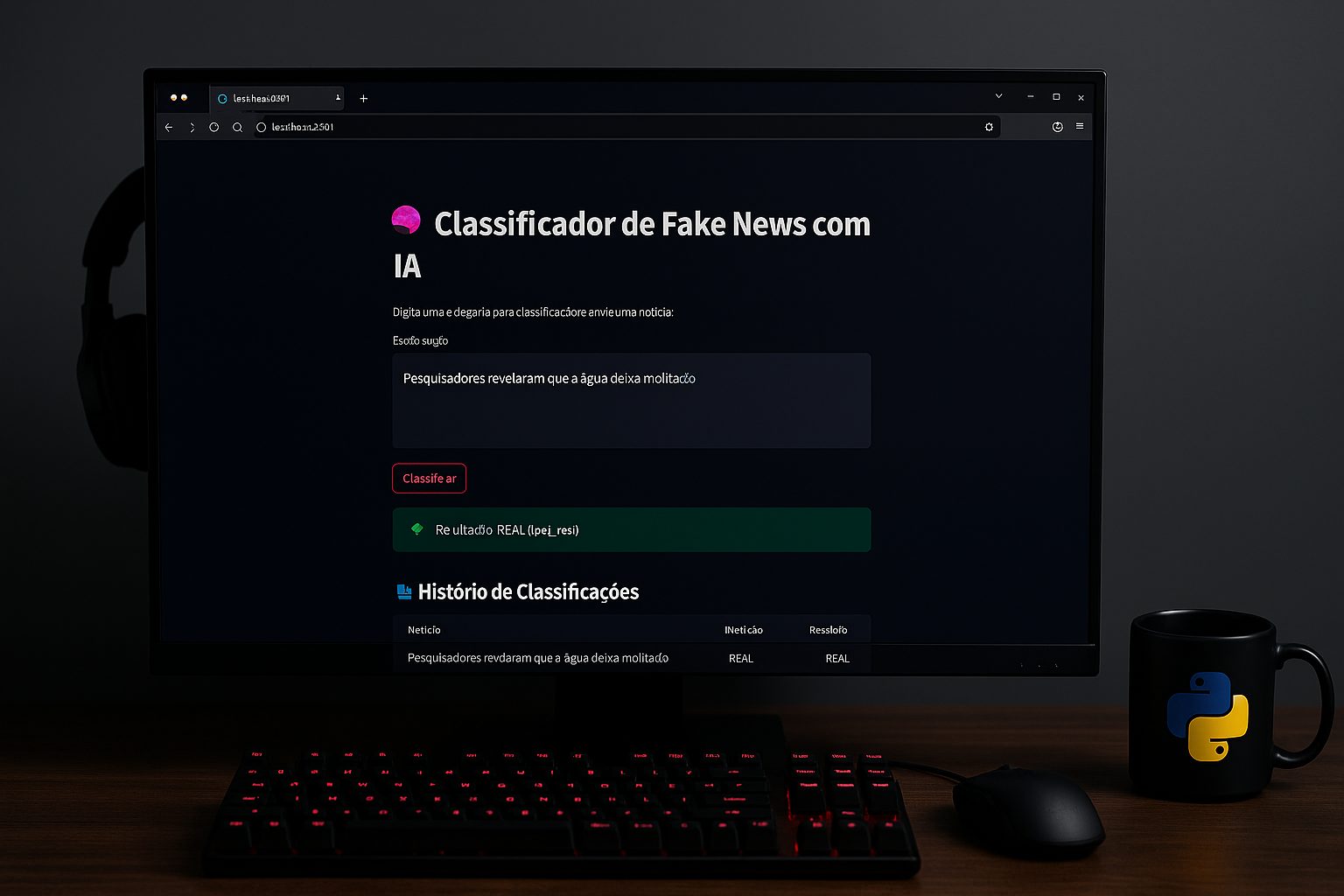
Um aplicativo web que:
✅ Permite digitar uma notícia
✅ Classifica como FAKE ou REAL
✅ Mostra o nível de confiança da IA
✅ Exibe o histórico das análises feitas durante a sessão
🧰 Tecnologias utilizadas
pandas— para manipular dadosscikit-learn— para treinar o modelo IATfidfVectorizer— para transformar texto em númerosLogisticRegression— classificador de textoStreamlit— interface web interativa
📦 Instalação dos pacotes necessários
Execute no terminal:
pip install pandas scikit-learn streamlit✍️ Código Final do Projeto — dia30.py
import streamlit as st
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# Carrega o dataset
df = pd.read_csv("fake_news_dataset_v2.csv")
df = df[['text', 'label']].dropna()
# Treinamento
vectorizer = TfidfVectorizer(stop_words='english', max_df=0.7)
X = vectorizer.fit_transform(df['text'])
y = df['label']
model = LogisticRegression()
model.fit(X, y)
# Interface
st.title("🧠 Classificador de Fake News com IA")
st.write("Digite uma notícia e descubra se ela é FAKE ou REAL.")
# Área de texto
noticia = st.text_area("📝 Sua notícia", height=150)
# Inicializa histórico na sessão
if 'historico' not in st.session_state:
st.session_state.historico = []
# Botão de classificação
if st.button("Classificar"):
if noticia.strip():
entrada_vec = vectorizer.transform([noticia])
pred = model.predict(entrada_vec)[0]
proba = model.predict_proba(entrada_vec).max() * 100
resultado = {
"Notícia": noticia,
"Classificação": pred,
"Confiança (%)": round(proba, 2)
}
st.session_state.historico.insert(0, resultado)
st.success(f"🧾 Resultado: **{pred}** ({round(proba, 2)}% de confiança)")
else:
st.warning("Digite uma notícia antes de classificar.")
# Histórico
if st.session_state.historico:
st.markdown("### 🕘 Histórico de Classificações")
st.dataframe(pd.DataFrame(st.session_state.historico))▶️ Como rodar o projeto corretamente
⚠️ Não execute com python dia30.py. Isso não vai abrir a interface.
✅ Use o comando correto:
streamlit run dia30.pyIsso abrirá automaticamente no seu navegador em:
http://localhost:8501🧠 O que você aprendeu hoje
- Como treinar um modelo IA com scikit-learn
- Como usar Streamlit para construir um app web sem frameworks complexos
- Como gerar resultados interativos e em tempo real para usuários
🎯 Desafio Final
- Publique seu app usando Streamlit Cloud
- Exporte o histórico como CSV
- Adicione barra lateral com configurações (ex: modelo, idioma, tema escuro)






